概述
金年会官方网站入口已经处于信息爆炸的时代,不计其数的互联网用户和机器间的连接导致数据呈爆发式增长,时至今日金年会官方网站入口获取的信息比以往任何时候都多,并且数据产生的速度仍然在高速增长。如图1所示:
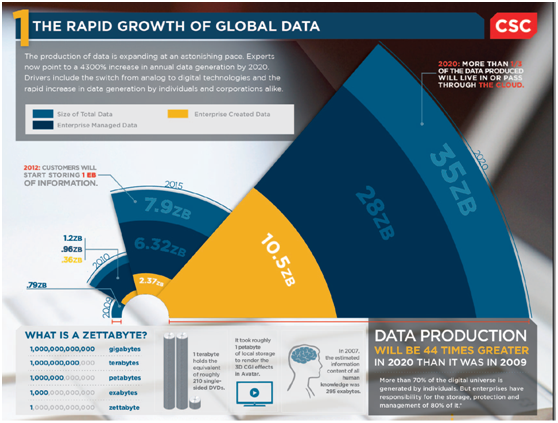
图1 Big Data: Unconstrained data growth
量变引起了质变,存储和分析快速增加的海量数据,为传统分析工具提出了新的挑战,金年会官方网站入口使用和分析数据的方式有了翻天覆地的变化。
Hadoop是当前流行的开源大数据存储和处理框架,具有高可靠性和扩展性,可以轻易地部署包括成千上万节点的集群。Hadoop由两大核心部件组成:一个分布式文件存储系统HDFS,解决了海量数据的存取问题;一个易于使用的MapReduce编程模型,使得海量数据的分析变得更加容易。
但是,MapReduce模型也存在一些问题,导致其未能达到理想性能,这些问题包括序列化的障碍增加了Reduce的时延、重复合并以及频繁的磁盘访问、缺乏支持高速互联技术等。在MapReduce执行期间,数据需要在各个DataNode之间传输,Map阶段处理好的数据,Shuffle之后递交给Reduce阶段。在此过程中,网络会是一个瓶颈,制约着Reduce的性能。基于RDMA协议的UDA(Unstructured Data Accelerator)插件可以加速Mapper-Reducer之间的数据传输,进而提高MapReduce的整体性能。
金年会官方网站入口RDMA解决方案
金年会官方网站入口科技的DxWay大数据服务器,板载自带Mellanox InfiniBand和10/40Gb 以太网 RoCE(RDMA over Converged Ethernet)自适应网卡,支持基于RDMA的UDA加速技术,以Hadoop插件的形式加速大数据的处理。
UDA使用基于network-levitated合并算法,在该算法中,数据直接在两个节点之间的内存里移动,省去了Shuffle、Merge以及Reduce过程中的序列化操作。RDMA(Remote Direct Memory Access)技术在加快Map和Reduce之间数据传输的同时,还可以将CPU从数据传输中解放出来,从而节省CPU资源。释放出来的CPU资源又可以启动新的数据进程,进而从总体上增加了系统的吞吐量。
UDA性能
使用UDA可以使大幅节省Reduce过程的执行时间,并提高吞吐量,可以提升50%。并且,数据集越大,越可以从UDA中受益。
以DxWay2040型号为例(2U4节点,每节点2颗E5-2620,32GB内存,使用Intel82599万兆以太网卡和Mellanox InfiniBand 10/40Gb网卡),对不同数据量下的时用时情况如下图所示:
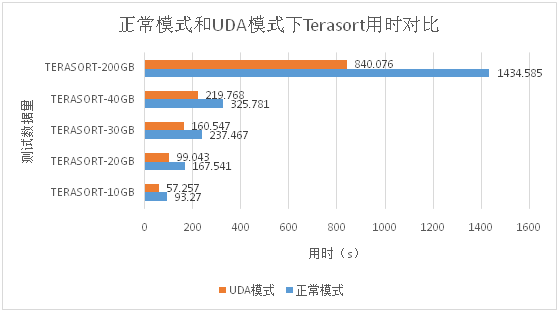
图2:正常模式和UDA模式下Terasort用时对比
对于CPU利用率,以Terasort-200GB数据量为例,其中一个节点的CPU利用率如图3、图4所示,未启用UDA功能时,CPU利用率如图3所示:
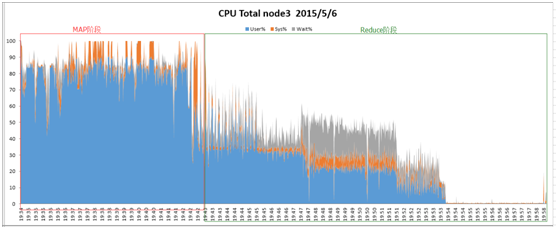
图3:未启用UDA时的CPU利用率
Reduce阶段,CPU利用率累加和大约为20707。
启用UDA功能时,CPU利用率如图4所示:
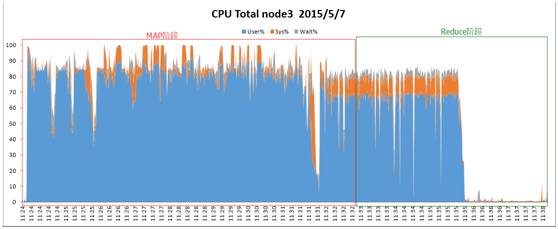
图4:启用UDA时的CPU利用率
Reduce阶段,CPU利用率累加和大约为13180。
由图3、图4可以看出,UDA模式下,Reduce过程大幅缩短,总体CPU使用率也比正常模式下低约36%。
结论
1)使用UDA功能时,可以有效降低MapReduce程序的用时,大约可以节约40%的时间。
2)使用UDA功能时,平均CPU利用率有所上升,但考虑到执行时间因素,Reduce阶段,UDA模式下的CPU利用率比正常模式低约36%。







